
Automation is great for taking care of routine tasks in IT Operations – but is it actually solving problems, or just hiding them temporarily?
One of the great things about computers is how easily you can automate away anything that annoys you. Any time you find yourself doing something repetitive, there is usually a way you can invest a little bit of time and effort up front to turn it into a bulk load or a job that will run on a regular basis. With a little more work, you can even trigger these automated actions when certain conditions are met, without having to invoke them manually or schedule them.
We are living in something of a golden age of automation, with high-quality tools available for any number of situations and requirements, whether they are free and open-source or commercial – or that grey area in between, with a free entry-level version and a Professional or Enterprise version with added capabilities that users can pay to upgrade to.
Most of the analysis around automation focuses on what the expected return is on the investment of automating a certain task. This calculation is generally run on the basis of how frequent the task is, how long it takes to perform by hand, and how much effort is required to automate it.
Of course this calculation can also go wrong, as XKCD reminds us:
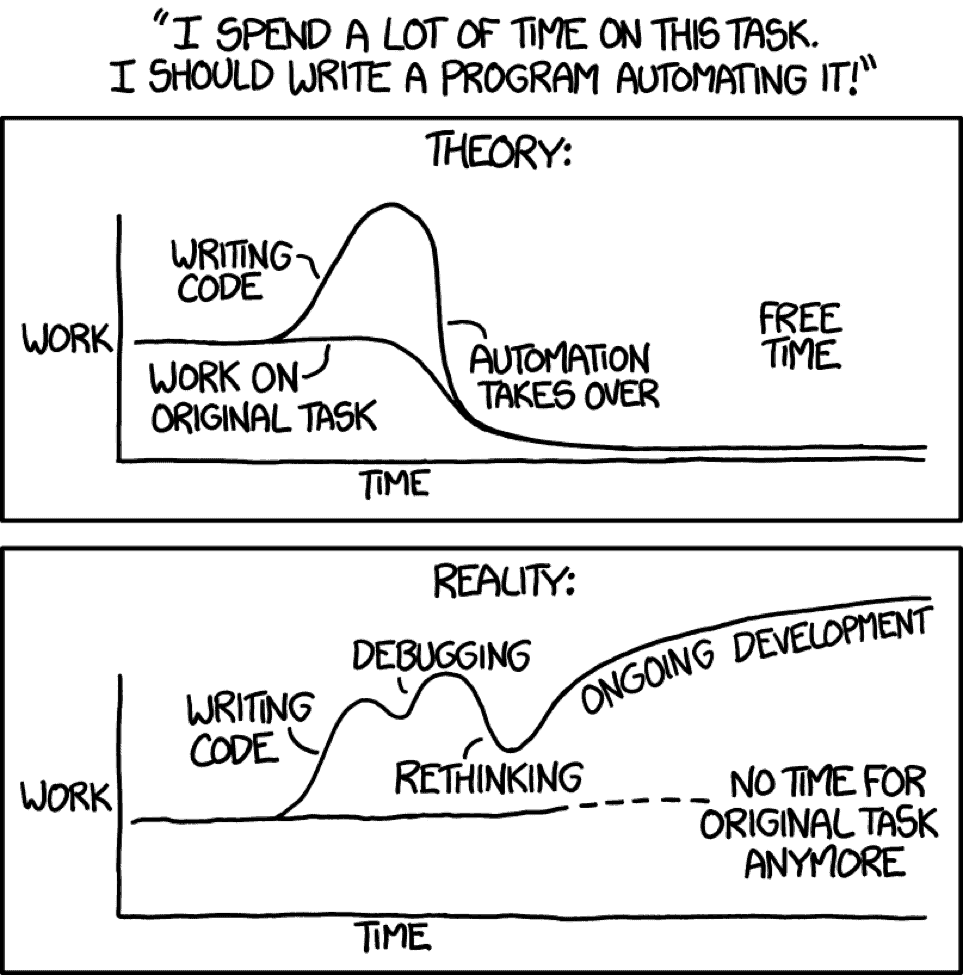
What can go wrong here?
This analysis of when to automate a task is all well and good, but it misses one of the biggest problems with automation. As the old saying goes, when all you have is a hammer, everything looks like a nail. If you have the ability to automate away annoying recurring tasks, you will be less likely to take a step back and consider why the task is recurring in the first place. Also, once a task has been automated, it is no longer going to be a priority in the same way as the issues that people are dealing with directly on a more regular basis – out of sight, out of mind.
Let’s make this a concrete example. It is annoyingly common in IT Operations that the known fix for an issue is to restart some component or another, often the web server. Logging in to a bunch of servers by hand to perform even such a trivial task takes time, plus there is always the risk of fat-fingering the command and taking down the wrong process. On the other hand, if you have a little script that will bounce Apache in a safe way, you can run that instead of logging in by hand every time. Even better, you can give that script to other people to run: share it with other people on your team, or give it to junior people so they don’t have to escalate simple issues that can be resolved by restarting httpd. For the ultimate in time saving, you can even wire things up so that the script will be triggered automatically any time a certain error condition is detected.
So far, so good; the problem is being solved, and in double-quick time, too!
Isn’t IT Operations about solving problems fast? What’s the problem?
Is that problem actually being solved? Is it not rather being swept under the carpet more efficiently?
If the web server needs to be restarted on a regular basis, should we not look at what is causing the problem? Maybe we have a problem in the application code, or maybe a different web server would be a better fit for our app’s architecture. After all, not everyone can rely on their memory leaks being addressed by the hardware exploding…
When incidents are assumed to be addressed in one area, by a single owner, it becomes very difficult to gain a true understand of the entire problem. The risk is that what looks initially like a perfectly reasonable solution from that limited perspective – “look at how short our resolution times are!” – may actually be counter-productive from a more holistic viewpoint. Restarting the web server may destroy valuable context that the developers would need in order to be able to craft a more permanent fix.
The problem is not the automation; that is just a tool, and a very useful one too. The problem is automation without visibility into the full context of a problem. Without that holistic view, automation is just plastering more bandaids onto a sucking chest wound faster and faster.
So how do we achieve better IT service management?
What is needed is a way to assemble a view of the entire context in which a problem occurs, and make that view available in a timely manner where it is needed by both humans and machines. In this way, application owners will be able to determine what is the most relevant action to take to resolve a particular issue, and do so with all the key facts available. Once that diagnosis has been made, a palette of applicable automated resolution actions can be offered, helping and guiding operators to restore service to users as quickly as possible.
By involving more people in that diagnosis, we can avoid using automation in wrong or inappropriate ways. The trick is, of course, to automate the process of assembling that contextual view of the problem and figuring out who are the right human specialists to invite to work together. Actually automating something is almost always the easy part. Figuring out what to do and when to do it –that is the hard part.
Gartner have come up with a model for how to take this more holistic approach, called Artificial Intelligence for IT Operations, or AIOps. This new discipline sits at the intersection of monitoring/observability, ticketing, and automation. The idea is to use machine learning and big-data techniques to assemble monitoring events into a coherent picture of what is happening, get the right people together to solve the problem, and give them a palette of automated actions to solve the problem. For more detail on AIOps, see this white paper including original research from Gartner as well as case studies from companies who have already adopted this model.
AIOps is the next big evolution in the world of IT Operations, and automation is key to delivering on AIOps. However, premature automation may be harmful, as it might be hiding information that Ops teams need to know. Look at the wider context to make sure automation is used in the right way.



